
Как собрать семантическое ядро

Семантическое ядро – это список слов, который максимально точно характеризует продвигаемый проект. Цель любого SEO-специалиста — сделать так, чтобы сайт показывался по максимально возможному списку ключевых слов в нужной тематике. Это возможно сделать только при грамотном и скрупулезном подборе семантического ядра.
Типы ключевых слов
Ключевые слова можно разделить на несколько признаков:
- По популярности.
- По зависимости от региона.
- По потребностям пользователей.
- По сезонности.
Рассмотрим каждый из них подробнее.
По популярности
Каждое ключевое слово имеет несколько типов частотности.
Частота запроса — количество запросов, или фраз, которые были набраны пользователем в поисковой системе в определённый промежуток времени. Способы определения частотности в Яндексе и Google отличаются. Ниже мы рассмотрим виды частотности ключевых слов, а также их разделение по популярности.
Итак, ключевые слова имеют следующие виды частотности (на основе сервиса wordstat.yandex.ru):
- Базовая — обозначает число показов по всем запросам с нужным словом. Например, если мы проверим в сервисе wordstat.yandex.ru ключевое слово «туры в египет», получим цифру в 83 567 показа в месяц. В этой цифре учтены все возможные словоформы: туров в Египет, турам в Египет, турами в Египет и т.д. Плюс добавляются варианты запросов: купить туры в Египет, туры в Египет цена и т.д.
- Фразовая — для определения фразовой частоты нужно взять запрос в кавычки. Таким образом отсекаются все добавочные слова, но учитываются словоформы, падежи и разные окончания. Например, запрос «купить туры в Египет» во фразовой частоте не учитывается, а запрос «турами в Египет» — учитывается.
- Точная — для определения точной частоты нужно взять запрос в кавычки и добавить к каждому слову в запросе восклицательный знак:

В этом варианте отсекаются добавочные слова, фиксируется словоформа, но не учитывается порядок слов. Например, запрос «турами в Египет» в точной частоте не учитывается, а запрос «в Египет туры» — учитывается.
Истинная – для определения истинной частоты к ключевому слову необходимо добавить [квадратные скобки], «кавычки» и восклицательный знак к каждому слову в запросе:

При сборе семантического ядра рекомендуем ориентироваться на точную или истинную частоту.
Отталкиваясь от частотности, ключевые слова можно разбить по популярности:
- НЧ (низкочастотные).
- СЧ (среднечастотные).
- ВЧ (высокочастотные).
Нельзя точно сказать порог частотности для той или иной группы. В одной тематике фраза может считаться НЧ, если у неё частотность 2 000 показов в месяц, в другой – 20.
При продвижении сайта необходимо уделять внимание низкочастотным запросам. Именно их легче всего продвинуть, и они будут давать основной трафик.
По зависимости от региона
Ключевые слова также можно разделить по зависимости от региона:
- Геозависимые — ключевые слова, которые зависят от того или иного региона. Например, запрос «купить телефон Казань» геозависим и будет показываться только в Казани и Казанской области.
- Геонезависимые — запросы, которые не зависят от региона. Например, запрос «как отремонтировать дверную ручку» будет считаться именно таковым.
По потребности
По потребности ключевые слова разделяются на следующие типы:
- Информационные — используются для поиска той или иной информации. Например, запрос «как приготовить борщ в пароварке» будет считаться информационным.
- Транзакционные — запросы, которые несут в себе то или иное действие. Пример транзакционных запросов: «купить ноутбук», «заказать эвакуатор», «доставка роллов», «скачать книгу» и т.д.
- Витальные — запросы, которые соответствуют какой-то компании или бренду. Вводя витальный запрос в поисковую строку, пользователь на первой строчке поисковой выдачи всегда будет видеть нужный сайт. Например, написав запрос «шанель», на первом месте пользователь увидит официальный сайт дома Chanel. А, например, написав запрос «купить шанель», пользователь увидит уже другие сайты, поскольку этот запрос является не витальным, а транзакционным. Витальные запросы можно не учитывать при сборе семантического ядра.
- Прочие запросы — те запросы, по которым не очевидно, что хочет найти пользователь. Например, введя в поисковую строку запрос «наполеон», пользователь может искать рецепт торта или информацию о полководце.
По сезонности
Некоторые ключевые слова имеют сезонность. Например, в тематиках «туры», «подарки на 23 февраля», «зимняя обувь» и т.д. сезонность очевидна. При сборе таких ключевых слов необходимо учитывать эту сезонность, проверить её можно с помощью сервиса wordstat.yandex.ru через функцию «история запросов»:

Маркерные запросы
Маркерные запросы (базисы) — это такие запросы, которые чётко отвечают продвигаемой странице. Как правило, такие запросы имеют значимую частотность и при добавлении вспомогательных слов (купить, цена, недорого) могут образовать «хвост» запросов.
Проще говоря, маркерные запросы — это такие запросы, которые могут служить названием категории. Например, для интернет-магазина электроники маркерными запросами могут быть:
- Телевизоры.
- Ноутбуки.
- Холодильники.
- Игровые ноутбуки.
- LCD-телевизоры и т.д.
По сути, самый полный список маркерных запросов мы собрали во втором уроке, когда проектировали черновой вариант структуры сайта. Теперь необходимо расширить данные маркеры и при необходимости удалить из структуры ненужные разделы (у которых нет частотности).
Важный момент! На одну страницу может вести несколько маркеров:
- Спецодежда.
- Спецовка.
- Рабочая одежда.
В таком случае в качестве основного запроса необходимо выбрать верный вариант написания «рабочая одежда», а с помощью синонимов расширять ядро.
Полезный совет! При работе с сервисом wordstat.yandex.ru рекомендуем использовать плагин для браузера Yandex Wordstat Assistant. Это бесплатный плагин, который позволяет выносить нужные фразы в отдельную колонку:

Берём названия категорий или услуг сайта и расширяем их логическими выводами:
Как и по каким запросам пользователи могут искать эту страницу моего сайта?
Все, что приходит на ум, забиваем в сервис wordstat.yandex.ru и все, что имеет частотность, добавляем в список маркеров.
Когда маркерные запросы собраны, можно переходить к их расширению (непосредственному сбору семантического ядра).
Сбор семантического ядра
Сервисы для составления семантического ядра
Инструментов для составления семантического ядра достаточно много. Ниже мы рассмотрим основные инструменты, которыми SEO-специалист пользуется ежедневно.
Яндекс Вордстат
Яндекс Вордстат — это бесплатный инструмент, который позволяет подбирать и анализировать ключевые слова. С помощью Яндекс Вордстат можно узнать:
● Статистику показов по ключевому слову в конкретном регионе.
● Статистику показов ключевого слова в мобильной выдаче.
● Статистику показов ключевого слова без учета словоформ и порядка слов (необходимо использовать операторы, о которых мы говорили выше).
● Дополнительные ключевые слова, которые могут быть использованы в ядре (правая колонка).
Однако это ещё не все. В сервисе работают различные операторы, которые позволяют:
Узнать статистику показов по ключевому слову без учета минус фраз. Например, если мы хотим узнать результаты по запросу «движение вверх» без учета слов «смотреть» и «скачать», перед этими словами следует поставить минус:

Узнать статистику показов по ключевому слову с учётом предлогов. Например, если мы хотим посмотреть все фразы с учётом предлога «как», перед предлогом нужно поставить знак +:

Просматривать статистику основного ключевого слова и его синонима. Для этого необходимо использовать оператор группировки – квадратные скобки и оператор «ИЛИ» - |:

Однако у сервиса есть существенные минусы:
- Нет автоматизации: все слова приходится собирать и чистить вручную, что занимает огромное количество времени (особенно если проект большой)
- Не учитываются подсказки, благодаря чему упускается огромное количество поисковых фраз.
Для сбора семантического ядра просто необходимо использовать сервисы автоматизации.
Key Collector
Key Collector — это обязательная программа для SEO-специалиста. Без неё просто невозможно обойтись, если вы планируете серьезно заниматься не только SEO, но и интернет-маркетингом в целом. Все дальнейшие действия по сбору ядра будут показаны именно на примере этой программы.
Вот только малая часть задач, которые решает Key Collector:
- Автоматический парсинг (подбор) ключевых слов из сервиса wordstat.yandex.ru.
- Автоматический парсинг поисковых подсказок.
- Автоматическая чистка ключевых слов.
- Фильтрация слов по частоте.
- Удаление дублей ключевых слов.
- Определение сезонности слов
- Сбор статистики с внешних сервисов, таких как Яндекс.Метрика, Google Analytics, Serpstat, Яндекс.Директ и т.д.
- Поиск релевантных запросам страниц.
- Сбор позиций ключевых слов и т.д.
Key Collector платный. На момент написания данного методического материала он стоит 1 800 рублей. Это цена пожизненной лицензии: заплатить нужно только один раз.
У программы есть «младший брат» — «СловоЁБ». Программа бесплатная, но с очень ограниченным функционалом. Кроме того, «СловоЁБ» не поддерживается уже несколько лет, поэтому актуальность сбора данных с его помощь под большим вопросом.
KeyAssort
KeyAssort — отличная программа кластеризации семантического ядра в автоматическом режиме, которая очень точно группирует запросы, на выходе создавая чистые группы.
Программа условно бесплатная. В демо-версии программы нет ограничений на кластеризацию или объём ядра, однако полученные данные вы не можете экспортировать. Расширенная лицензия будет стоить 2 000 рублей единоразово.
Букварикс
Из очевидных плюсов:
- В базе мало мусора.
- Есть готовый список минус-слов по различным тематикам.
- Ключевые слова идут сразу с частотностью (пусть примерной, но всё-таки).
- Есть возможность экспорта ключевых слов.
- Есть возможность забрать ключевые слова конкурентов.
Serpstat
Serpstat — это многофункциональный, но платный SEO-сервис.
С помощью данного инструмента можно проанализировать ключевые фразы, подобрать ключевые слова конкурентов, подобрать высоко-, средне- и низкочастотные фразы. Всё это можно делать как на основе поисковой системы Яндекс, так и Google.
С помощью данного инструмента можно получить такие данные:
- Частотность ключевого слова.
- Приблизительную стоимость клика по ключу в контекстной рекламе.
- Динамику популярности ключевого слова.
- Список конкурентов в органике и контекстной рекламе.
В разделе «SEO-анализ» для базового ключевого слова можно подобрать похожие слова и поисковые подсказки. В этом же разделе можно видеть список страниц из ТОПа по тому или иному запросу.
Кроме всего прочего, Serpstat позволяет выгружать ключевые слова конкурентов.
Это базовый список инструментов, с помощью которых можно быстро собрать качественное семантическое ядро. Переходим к практике.
Сбор семантического ядра в Key Collector
Ниже будет описана последовательная и логичная система, которая позволит вам собирать семантическое ядро на профессиональном уровне. В работе мы будем использовать программу Key Collector, поскольку это самый удобный и дешёвый инструмент для быстрого сбора ключевых слов.
Настройка программы
Прежде чем приступить к сбору ключевых слов, необходимо правильно настроить программу. Заходим в программу и кликаем по шестерёнке:

На вкладке «Общие» ставим примерно следующие настройки:
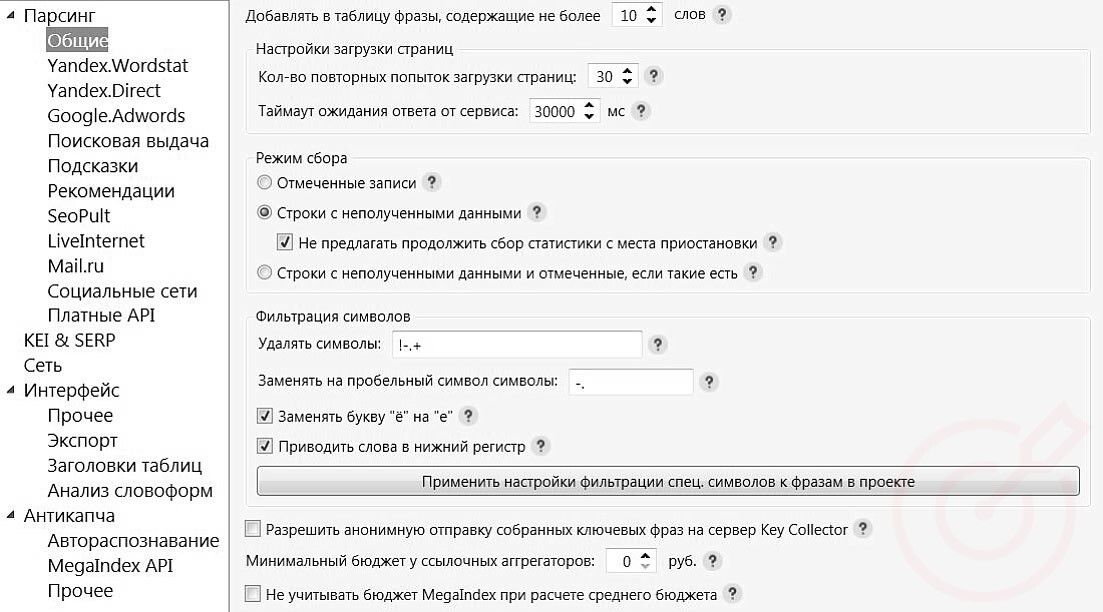
На вкладке «Yandex.Wordstat» ставим примерно следующие настройки:

На вкладке «Yandex.Direct» с помощью кнопки «Добавить списком» добавляем аккаунты Яндекс.Директ.
Обратите внимание! Аккаунты для Яндекс.Директ нужны для быстрого сбора частотности. Категорически не рекомендуется для этих целей использовать рабочий аккаунт на Яндексе. Для этой цели лучше самостоятельно зарегистрировать несколько десятков «левых» аккаунтов, либо приобрести их.
Настройки на этой вкладке должны быть примерно следующими:

На вкладке «Google Adwords» делаем то же самое. С одной поправкой: не нужно задавать больше одного аккаунта без явной необходимости:

На вкладке «Подсказки» настройки ставим примерно такими:

Теперь переходим на вкладку «Платные API» и при необходимости добавляем API нужных сервисов. В нашем случае необходимо добавить токен сервиса Serpstat со следующими настройками:

Токен Serpstat можно взять в личном кабинете сервиса. Для этого перейдите в личный кабинет сервиса. Теперь переходим на вкладку «Экспорт» и ставим там примерно такие настройки:

Далее переходим в раздел «Анализ словоформ» и ставим следующие настройки:

Последним шагом будет настройка антикапчи. При сборе большого семантического ядра через сервисы Яндекса или Google периодически будет выскакивать капча (код, который просит подтвердить, что вы не робот).
Чтобы не вводить эти коды самостоятельно, существуют сервисы по автоматическому распознаванию капчи. Мы рекомендуем использовать сервис rucaptcha.com/ru. Заведите на сервисе аккаунт, пополните баланс на 100 рублей (этого хватит на несколько месяцев) и подключите его в Key Collector в разделе «Автораспознавание»:

На этом основные настройки закончены. Сохраняем изменения и создаем новый проект:

Установка региональности
После создания нового проекта на панели региональности необходимо установить нужный регион (тот регион, по которому планируется продвижение). Именно по этому региону будет сниматься частотность ключевых слов:

Если при сборе ядра вы планируете охватить максимальное количество регионов, то ставьте регион «Россия».
Группировка маркерных слов для парсинга
Собрав маркерные запросы, мы сгруппировали их в логическую структуру, которую мы будем использовать для парсинга. Группы можно создать вручную, используя панель «Управление группами»:

Однако если групп очень много, то такая процедура займет много времени. К счастью, создание групп можно автоматизировать.
Нажимаем на кнопку «Добавить фразы»:

В открывшемся окне нажимаем на шестерёнку, ставим галочку напротив пункта «Использовать режим импортирования “Группа:Ключ”». Закидываем наши группы в таком формате:

В итоге все группы добавляются автоматически:

Теперь эти группы необходимо расширить.
Сбор семантического ядра из разных источников
Теперь необходимо в каждую группу добавить ключевые слова. Необходимо использовать следующие источники:
- Wordstat.yandex.ru.
- Поисковые подсказки Яндекс и Google.
- Serpstat (сбор расширений ключевых фраз).
Действуем по следующей схеме:
- Активируем инструмент парсинга по Wordstat.
- В открывшемся окне используем распределение по группам.
- Переносим название групп, которые мы назвали названием начальных ключей.
- Удаляем лишние группы из плана сбора, чтобы не тратить время и ресурсы.
- Начинаем сбор данных из Яндекс.Вордстат.
Пример:

Аналогично действуем с другими источниками.
Важный момент! В окно с каждым ключом можно и нужно вводить фразы-синонимы, а также разные словоформы, чтобы собрать наибольший список ключевых фраз.
После нажатия на кнопку «Начать сбор» необходимо немного подождать. Когда сбор закончится, можно переходить к съёму частотности.
Сбор частотностей ключевых слов
Для сбора частоты всех фраз мы будем пользоваться сервисом Яндекс.Директ. Необходимо сделать следующее:
- Выбрать группы, для которых нужно собрать частоту, и включить режим «Мультигруппы».
- Открыть окно для сбора данных их Яндекс.Директ.
- Выбрать режим «Спецразмещение».
- Выбрать период сбора «Месяц», если тематика сезонная – «Год».
- Отметить цель сбора и виды собираемых частот.
- Начать сбор данных.
Пример:

После завершения сбора используем инструмент «Автонастройка видимости колонок», он уберёт из рабочей области столбцы, по которым нет данных:

Когда всё сделано, необходимо осуществить чистку запросов.
Чистка ключевых слов
Удаление нулевых запросов. С помощью фильтров убираем все ключевые слова с частотностью «0» и пустым значением. Сразу сохраняем этот фильтр, поскольку он нам неоднократно потребуется при сборе других семантических ядер:

Важный момент! Все фильтры, которыми вы периодически пользуетесь, необходимо сохранять. Так вы существенно сэкономите время.
После этих манипуляций выделяем ключевые слова и удаляем их:

Анализ неявных дублей. Анализ неявных дублей делаем следующим образом:
- Переходим в «Данные» ➔ «Анализ неявных дублей».
- Разворачиваем пункт «Выбрать параметры умной групповой отметки».
- Выбираем «Отметить все, кроме самой высокочастотной фразы в каждой группе».
- Выбираем частотность, на которую будем ориентироваться.
- Нажимаем «Выполнить поиск дублей повторно».

Все неявные дубли удаляем.
Удаление спецсимволов. С помощью фильтров удаляем все спецсимволы. Как правило, они не имеют частотности и в большинстве случаев являются мусорными:

Удаление повторов слов. Аналогично предыдущему пункту повторы являются мусорными словами, поэтому их необходимо удалять:

Чистка от нерелевантных запросов. Чтобы вручную не проходить по всем ключевым словам, воспользуемся инструментом «Анализ групп». С помощью этого инструмента мы отмечаем нецелевые слова, попутно их минусуя:

Важный момент! В некоторых группах могут быть как целевые, так и нецелевые ключи. Можно отметить группу полностью и нажатием на плюс посмотреть, какие слова внутри. Если в группе есть целевая фраза, то с нее отметку можно убрать.
Чистка по стоп-словам. В меню выбираем инструмент «Стоп-слова». В нём уже находятся те слова, которые вы добавили при анализе групп. Подборку можно отметить в таблице:

Удаление фраз, которые содержат в себе больше 7 слов. Как правило, фразы, состоящие из 7 и более слов, по большей части спамные, имеют низкую частотность и их крайне сложно использовать в тексте. Также если посмотреть ТОП по длинным фразам, их прямых вхождений в тексте вы не найдете, поэтому нет смысла в сборе таких слов.

Экспорт ключевых слов
Когда все ключевые слова собраны, разбиты по группам и почищены, их необходимо выгрузить из программы Key Collector. Делается это следующим образом:
- Выделяем все группы, которые необходимо выгрузить.
- Включаем режим мультигрупп.
- Нажимаем на кнопку «Экспорт в xls:

На выходе получаем такой файл:

На этом всё. Это необходимый минимум в работе с программой для сбора хорошего семантического ядра. Вышеописанные манипуляции необходимо повторить со всеми маркерными запросами.
Инструменты для сбора семантического ядра
- Key Collector — программа для составления семантического ядра.
- Excel — потребуется для импорта и дальнейшей работы с семантическим ядром.
- KeyAssort — программа для автоматической кластеризации ключевых слов.
- Wordstat — потребуется для ручного сбора ключевых слов.
- Yandex Wordstat Assistant — браузерный плагин для работы с сервисом Яндекс.Вордстат.
- Serpstat — потребуется для расширения списка ключевых слов.
- Букварикс — потребуется для расширения списка ключевых слов.
Публикация ➔ TotalShiva